PointNet++ - Deep Hierarchical Feature Learning on Point Sets in a Metric Space 리뷰
오늘 소개드릴 논문은 Stanford에서 2017년 NIPS에 발표한 Pointnet++: Deep hierarchical feature learning on point sets in a metric space 논문에 대한 리뷰입니다.
이 논문은 Point cloud 형식의 데이터를 Deep learning 분야에 적용시킨 선구적인 논문인 PointNet의 후속편으로, local한 특징을 잡아내지 못하는 기존의 PointNet을 보완하여 classification 및 segmentation 성능을 크게 끌어올렸습니다. 그럼 PointNet++에 대한 리뷰를 시작하겠습니다!
PointNet
Point cloud는 3차원 공간 내의 물체를 표현하기 위한 데이터의 형식 중 하나로, 각 점들에 대한 xyz 좌표 및 특징을 담은 벡터들로 구성되어 있습니다. Point cloud는 sparse한 점들에 대한 집합(Set) 형태의 데이터이기 때문에 계산량 및 메모리 차원에서 효율적입니다. 하지만 점들의 순서가 정해져있지 않은 permutation-invariant한 특성 때문에, neural network의 입력으로 활용하려면 순서에 관계없이 항상 같은 결과를 도출해주는 연산 과정이 필수적입니다. PointNet에서는 symmetric한 특성을 가진 max-pooling 함수를 활용하여 point cloud의 global feature를 추출하였습니다. 하지만 max-pooling 함수의 특성상 최대값을 제외한 local한 정보들은 소실될 수밖에 없고, 이는 정교한 경계선 설정이 중요한 segmentation task에서 성능 저하의 요인이 되었습니다. PointNet++은 local한 정보를 담은 특징 벡터를 추출하여 정확도 측면에서 PointNet을 개선한 모델입니다.
Local한 특징 벡터를 추출하는 것은 중요합니다. CNN에서도 다양한 receptive field를 가지는 convolution kernel을 활용함으로써 local한 특징을 추출하였고, 이는 2D image들에 대한 폭발적인 성능 향상을 이뤄냈습니다. PointNet++는 계층적 형태의 U-Net 구조를 활용하여 다양한 scale의 local feature를 추출하였고, 이를 통합하여 SOTA의 classification 및 segmentation 성능을 기록할 수 있었습니다. 그럼 PointNet++에 대해 좀 더 자세히 알아보겠습니다.
PointNet++
 PointNet++는 크게 Set abstraction layer 과 Density adaptive layer 로 구성되어 있습니다.
PointNet++는 크게 Set abstraction layer 과 Density adaptive layer 로 구성되어 있습니다.
Set Abstraction
Set abstraction은 PointNet++에서 point cloud의 local feature를 추출하기 위해 사용한 방법입니다. Point cloud가 set abstraction 과정을 거치게 되면, 전반적인 semantic 정보를 포함한 압축된 point cloud로 변환됩니다.
Set abstraction layer는 세 가지 layer로 구성되어 있습니다. 우선 Sampling layer 에서는 입력 point cloud에서 중심이 되는 몇개의 점들을 선택합니다. 이 때 선택된 점들은 이전 point cloud의 대표성을 잃지 않아야 하며, local한 공간의 중심이 되어야 합니다. 이후 Grouping layer 에서는 sampling layer에서 찾은 각 중심점에 대하여 이웃한 점들을 찾고, 이를 묶어서 하나의 점묶음으로 구성합니다. 마지막으로 PointNet layer 에서는 각 점묶음에 포함된 점들의 패턴을 파악하여 점묶음별로 특징 벡터를 추출합니다.
예를 들어, 어떤 point cloud가 N 개의 점들로 구성되어 있고 각 점은 xyz 좌표와 C 차원의 특징 벡터를 가진다고 가정하겠습니다. 이는 N x (3+C) 의 크기를 가진 행렬로 표현이 가능한데, set abstraction layer 를 거치게 된다면 N’ x (3+C’) 크기의 point cloud로 변환됩니다. 이 때 N’ 는 subsampling된 점들의 개수이고, C’ 는 출력된 특징 벡터의 차원입니다.
먼저 Sampling 단계에서는 N 개의 점들 중 N’ 개 점들을 중심점으로 선택합니다. 이 때 중심점이란 전체 점들 중 서로 간의 Uclidian distance가 가장 먼 점들을 의미합니다. 이렇게 서로 간의 거리가 가장 먼 점들을 선택하는 과정을 Farthest point sampling (FPS) 이라고 부릅니다. 서로 가장 멀리 떨어져 있는 점들을 선택하게 되면, 임의로 점들을 선택하는 것보다 더 일반적이고 대표성을 띄는 점들을 얻을 수 있습니다.
이후 Grouping 단계에서는 sampling 단계에서 추출한 각 중심점과 그 주변 점들을 점묶음으로 묶어줍니다. 점묶음을 구성하는 점들의 개수는 조금씩 달라질 수 있는데, 이어지는 PointNet 단계에서 점묶음마다 점들의 개수에 상관없이 고정된 크기의 특징 벡터를 하나씩 추출해주기 때문입니다. 중심점에 대해 이웃한 점들을 정의하는 방식도 ball query 와 KNN 의 두 가지가 있습니다. 우선 ball query 방식은 반지름 r 을 정하고, 중심점을 기준으로 반지름 내에 있는 모든 점들을 이웃한 점으로 정의합니다. 또한 KNN 방식은 중심점에 대해 가장 가까운 K개의 점을 이웃한 점으로 정의합니다. PointNet++에서는 주변 점들을 ball query 방식으로 정의했는데, 정해진 크기의 영역만을 포함하는 고정적인 범위의 점묶음을 형성할 수 있기 때문입니다. 이는 점밀도가 일정하지 않은 point cloud의 경우에 점묶음별로 범위가 달라지는 문제를 방지할 수 있습니다.
마지막으로 PointNet 단계에서는 각 중심점과 주변 점들의 특징 벡터를 PointNet에 통과시켜 하나의 특징 벡터를 추출합니다. Point cloud의 모든 점묶음들은 N’ x K x (3+C’) 크기의 행렬로 표현할 수 있는데, 각 중심점별로 PointNet을 통과하면 N’ x (3+C’) 크기의 행렬로 변환됩니다. 이 때 절대적인 xyz 좌표값이 아닌 중심점과의 상대적인 좌표값을 입력으로 이용하였는데, 이를 통해 점들 간의 위치적 관계에 대한 정보를 담을 수 있기 때문입니다.
Density Adaptive Feature Learning

Point cloud 데이터는 대부분 위의 그림처럼 일정하지 않은 밀도로 분포되어 있습니다. 조밀한 밀도 분포를 가진 point cloud에 대해 학습한 네트워크는 sparse한 point cloud를 만났을 때 정보가 부족하다고 느끼고 특징을 제대로 파악하지 못합니다. 마찬가지로 sparse한 point cloud로 학습한 네트워크의 경우 dense한 point cloud가 들어왔을 때, 다른 분포의 데이터 때문에 좋은 성능을 보이지 못합니다.
이렇게 점들의 밀도가 일정하지 않은 특성은 point cloud의 일반적인 학습을 어렵게 만드는데, 논문에서는 이를 해결하기 위해 point cloud를 다양한 밀도로 sampling하여 학습하였습니다. 일종의 data augmentation이라고도 볼 수 있을 것 같습니다. 또한 다양한 scale의 point cloud에서 특징 벡터를 추출하는 네트워크 구조를 활용하였는데, 이를 density adaptive layer 라고 부릅니다. 다양한 크기를 가지는 point cloud를 학습하는 두 가지 방법에 대해 소개하겠습니다.

- Multi-scale grouping (MSG)
우선 grouping 단계를 다양한 scale로 여러 번 적용하여 하나의 중심점에 대해 여러 scale의 point group을 얻는 방법이 있습니다. 각 point group에서 각각 추출한 feature vector를 이어붙이면(concatenate), multi-scale feature vector를 얻을 수 있게 됩니다. 이 때, 각 point group은 임의의 dropout ratio를 선택하여 그 비율에 맞게 random하게 down-sampling(dropout) 하여 각 point group마다 서로 다른 scale로 균일하지 않은 density를 가지게끔 변환해주었습니다. 이러한 과정을 거치면 다양한 sparsity와 서로 다른 uniformity를 가지는 점들을 얻을 수 있습니다. 하지만 MSG는 각 중심점들과 그 이웃한 점들이 모두 pointnet을 거쳐야 하므로 게산량 차원에서 아주 비효율적이고 time-consuming하다는 단점이 있습니다. 논문에서는 이를 보완하기 위해 multi-resolution grouping을 제안하였습니다.
- Multi-resolution grouping (MRG)
MRG는 MSG의 단점을 보완한 grouping 방식입니다. MRG는 서로 다른 scale로 얻은 두 feature vector를 이어붙여서(concatenate) multi-scale feature vector를 얻습니다. 이 때, 첫 번째 vector는 local group에 해당하는 점들 전체에 대해 pointnet 단계를 거쳐서 얻고, 두 번째 vector는 local group에 대해 그보다 한 단계 아래의 sub-region에서 얻은 feature를 종합하여 얻습니다. 저자는, 만약 input으로 들어오는 point cloud의 density가 낮다면, 첫 번째 vector에 의해 전반적인 특징에 대한 정보를 추출할 수 있고, density가 높다면, sub-region에 대한 feature가 높은 resolution 더 디테일한 특징 정보를 제공할 수 있다고 이야기합니다. 따라서 두 vector를 모두 이용하게 되면 여러 density의 point cloud에 대해서 모두 대응할 수 있으며, 계산량 측면에서도 효율적이라고 말합니다.
Point Feature Propagation
Set abstracion layer를 거치게 되면, sampling 단계에 의해 point cloud의 크기가 줄어들게 됩니다. 이렇게 얻은 feature vector를 segmentation task에 활용하려면 다시 원래의 크기로 복원해주어야 합니다. 복원해주지 않고 set abstraction을 하기 위해 모든 점들을 중심점으로 지정해서 feature aggregation을 해주는 방법도 있지만, 이는 computation cost가 너무 많이 들기 때문에 논문에서는 point cloud를 down-sampling하고 다시 interpolation 기반의 방법을 통해 up-sampling하는 방식을 제안하고 있습니다.
구체적으로, 이전 점들에 대한 feature vector로부터 (1/거리값) 으로 weighting을 가해서 interpolation하는 방법을 이용하였습니다. 또한 down-sampling 되기 전의 feature vector를 skip-connection을 통해 concatenate하여 부족할 수도 있는 정보량을 보충해주었습니다. Interpolation 과정은 원래 point의 개수로 맞춰질 때까지 반복해주었고, 결과로 얻은 feature vector를 통해서 segmentation task를 수행해주었습니다.
Experiments
PointNet++는 MNIST(2D Object), ModelNet40(3D Object), ScanNet(3D Scene) 등의 다양한 데이터셋에 대한 evaluation 과정을 통해 classifiaction 및 segmentation task에서 성능을 증명하였습니다.
-
MNIST
 MNIST 데이터셋은 손글씨 숫자에 대한 60,000개 이상의 image입니다. PointNet++는 2D image의 좌표를 2D point cloud 형태로 변환하여 input으로 사용했는데, 기존 PointNet과 비교했을 때 error rate이 30% 이상 감소하는 등의 성능 향상을 보여주었습니다. 또한 기존 CNN 기반의 모델들과 비교했을 때도 더 좋은 성능을 보이기도 했습니다.
MNIST 데이터셋은 손글씨 숫자에 대한 60,000개 이상의 image입니다. PointNet++는 2D image의 좌표를 2D point cloud 형태로 변환하여 input으로 사용했는데, 기존 PointNet과 비교했을 때 error rate이 30% 이상 감소하는 등의 성능 향상을 보여주었습니다. 또한 기존 CNN 기반의 모델들과 비교했을 때도 더 좋은 성능을 보이기도 했습니다. -
ModelNet40
 ModelNet40 데이터셋은 40개의 클래스에 대한 CAD 모델입니다. CAD 모델은 3D Mesh 형태를 띄고 있기 때문에, 논문에서는 mesh의 표면을 sampling하여 3D point cloud 형태로 변환한 후에 PointNet++의 input으로 사용하였습니다. 또한 모델 구조는 3단계의 계층 단계에 3개의 Fully connected layer를 이어붙여서 구성했으며, 모든 point들의 좌표는 반지름 1의 구 안에 들어오게끔 하여 normalization을 해주었습니다. PointNet++는 3D classification task에서도 기존의 SOTA 모델로 알려진 MVCNN의 성능을 크게 뛰어넘었습니다.
ModelNet40 데이터셋은 40개의 클래스에 대한 CAD 모델입니다. CAD 모델은 3D Mesh 형태를 띄고 있기 때문에, 논문에서는 mesh의 표면을 sampling하여 3D point cloud 형태로 변환한 후에 PointNet++의 input으로 사용하였습니다. 또한 모델 구조는 3단계의 계층 단계에 3개의 Fully connected layer를 이어붙여서 구성했으며, 모든 point들의 좌표는 반지름 1의 구 안에 들어오게끔 하여 normalization을 해주었습니다. PointNet++는 3D classification task에서도 기존의 SOTA 모델로 알려진 MVCNN의 성능을 크게 뛰어넘었습니다.
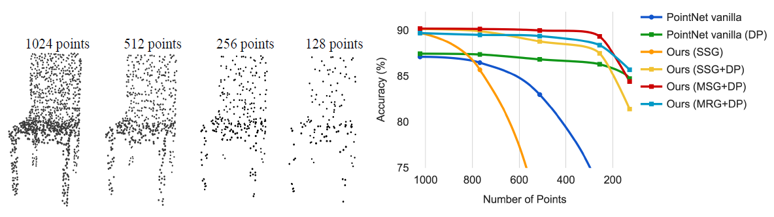 또한 ModelNet 데이터셋을 활용하여 Density adaptive layer의 성능을 측정하는 ablation study를 진행했습니다. 위의 그림을 보면, 1024개의 점에 대한 point cloud로부터 random하게 점을 지워서 512, 256, 128개로 down-sampling하였습니다. 점의 개수가 다른 point cloud를 PointNet 및 PointNet++의 input으로 넣어주었을 때, 앞서 설명드린 density aadaptive layer (MSG 또는 MRG)를 적용시켜 multi-scale로 학습한 모델들은 점의 개수가 달라져도 robust한 결과를 보여주었습니다.
또한 ModelNet 데이터셋을 활용하여 Density adaptive layer의 성능을 측정하는 ablation study를 진행했습니다. 위의 그림을 보면, 1024개의 점에 대한 point cloud로부터 random하게 점을 지워서 512, 256, 128개로 down-sampling하였습니다. 점의 개수가 다른 point cloud를 PointNet 및 PointNet++의 input으로 넣어주었을 때, 앞서 설명드린 density aadaptive layer (MSG 또는 MRG)를 적용시켜 multi-scale로 학습한 모델들은 점의 개수가 달라져도 robust한 결과를 보여주었습니다. -
ScanNet
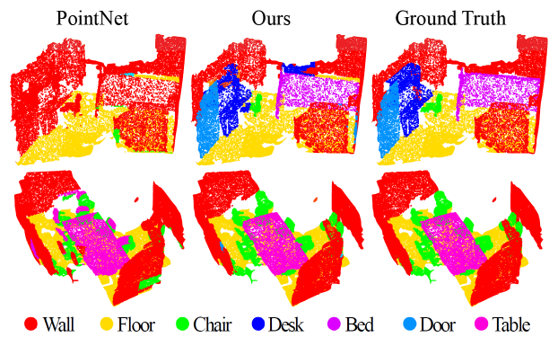
ScanNet 데이터셋은 실내 환경에 대한 1500개 이상의 3D point cloud 데이터로 구성되어 있습니다. 각각의 점들에는 해당 점이 어떤 물체에 속해 있는지에 대한 segmentation label이 달려 있습니다. PointNet++는 ScanNet에 대한 segmentation task에서도 아주 뛰어난 결과를 보여주었습니다. 계층적 구조를 통한 local한 feature 학습이 다양한 scale의 scene을 이해하는데 중요하다고 해석할 수 있을 것 같습니다.
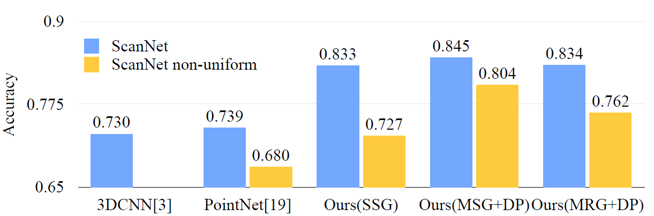
 ScanNet에서도 sampling density가 달라졌을 때 robust한 결과를 도출할 수 있는지 실험하였습니다. ScanNet 데이터를 non-uniform한 sampling density로 줄여서 학습한 뒤에 결과를 확인해보았습니다. 앞선 ModelNet40을 이용한 실험 결과와 마찬가지로, MRG 네트워크가 Single-scale grouping을 통해 학습한 네트워크보다 다양한 density의 데이터들에 대해 훨씬 더 좋은 결과를 보여주었습니다.
ScanNet에서도 sampling density가 달라졌을 때 robust한 결과를 도출할 수 있는지 실험하였습니다. ScanNet 데이터를 non-uniform한 sampling density로 줄여서 학습한 뒤에 결과를 확인해보았습니다. 앞선 ModelNet40을 이용한 실험 결과와 마찬가지로, MRG 네트워크가 Single-scale grouping을 통해 학습한 네트워크보다 다양한 density의 데이터들에 대해 훨씬 더 좋은 결과를 보여주었습니다.
Summary
PointNet과 더불어 PointNet++는 이전에 classification이나 detection 분야에서 활용되었던 multi-scale feature learning 기법을 point cloud 데이터에 적용시켜 급격한 성능 향상을 만들었습니다. 또한 Graph의 크기를 줄이는 graph coarsening이나 다시 graph의 크기를 키우는 point feature propagation 등 다양한 개념이 제시된 논문이라 의미가 크다고 생각합니다. 다음 번에는 이를 기반으로 attention 메커니즘을 적용시킨 논문을 한번 리뷰해보겠습니다. 읽어주셔서 감사합니다 :)
참고 문헌 및 출처